Emerging Platforms Meet Emerging LLMs: A Year-Long Journey of Top-Down Development
Abstract
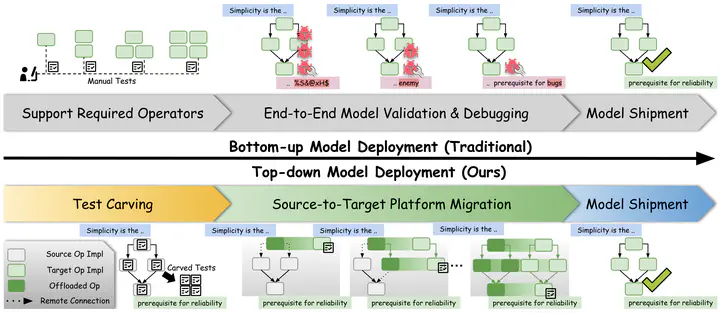
Deploying machine learning (ML) on diverse computing platforms is crucial to accelerate and broaden their applications. However, it presents significant software engineering challenges due to the fast evolution of models, especially the recent Large Language Models (LLMs), and the emergence of new computing platforms. Current ML frameworks are primarily engineered for CPU and CUDA platforms, leaving a big gap in enabling emerging ones like Metal, Vulkan, and WebGPU. While a traditional bottom-up development pipeline fails to close the gap timely, we introduce TapML, a top-down approach and tooling designed to streamline the deployment of ML systems on diverse platforms, optimized for developer productivity. Unlike traditional bottom-up methods, which involve extensive manual testing and debugging, TapML automates unit testing through test carving and adopts a migration-based strategy for gradually offloading model computations from mature source platforms to emerging target platforms. By leveraging realistic inputs and remote connections for gradual target offloading, TapML accelerates the validation and minimizes debugging scopes, significantly optimizing development efforts. TapML was developed and applied through a year-long, real-world effort that successfully deployed significant emerging models and platforms. Through serious deployments of 82 emerging models in 17 distinct architectures across 5 emerging platforms, we showcase the effectiveness of TapML in enhancing developer productivity while ensuring model reliability and efficiency. Furthermore, we summarize comprehensive case studies from our real-world development, offering best practices for developing emerging ML systems.